时序预测模型
在阅读本文档之前,建议先阅读 TSDataset 文档 ,以了解TSDataset的设计。 简单来说,TSDataset是PaddleTS中贯穿整个建模生命周期的、统一的时间序列数据结构。它引出了几个基本但重要的时间序列相关概念,例如待预测目标(过去目标、未来目标)以及协变量(观测协变量和未来已知协变量)。对这些概念的理解将有助于深入探究该文档并构建性能良好的模型。
从一个较高的视角来看,PaddleTS 提供了以下三个时序建模相关的特性:
标准化的接口。 这些在 PaddleBaseModel 中声明的 fit、predict 标准化接口接收、返回统一的 TSDataset 数据集,作为其输入输出,以便将一些数据集处理和样本构建的复杂细节封装起来,简化API的使用,降低学习成本。
PaddleTS 设计了 PaddleBaseModelImpl 类,该类包含一组覆盖整个建模生命周期的通用函数与组件(如 准备样本,初始化模型性能指标, 计算损失等)。这使得用户可以更关注深度网络架构本身,同时也为广大开发者基于PaddleTS构建新的时序模型提供了最大程度的便利。
开箱即用的模型。PaddleTS提供一组预定义的,开箱即用的时序深度学习模型:
1. 一个最小化的示例
下方的最小化示例使用了PaddleTS内置的 RNNBlockRegressor 模型来阐述基本的使用方法。
from paddlets import TSDataset
from paddlets.models.model_loader import load
from paddlets.models.forecasting import RNNBlockRegressor
# 1 prepare the data
data = TSDataset.load_from_csv("/path/to/data.csv")
# 2 data preprocessing and feature engineering
# NB:
# Consider simplifying the example, all these important processes are skipped here.
# Please refer to the following documentation to get more details if needed:
# https://paddlets.readthedocs.io/en/latest/source/modules/transform/overview.html
# 3 init the model instance.
model = RNNBlockRegressor(in_chunk_len=96, out_chunk_len=96)
# 4 fit
model.fit(train_tsdataset=data)
# 5 predict
predicted_dataset = model.predict(data)
# 6 recursive predict
recursive_predicted_dataset = model.recursive_predict(data, predict_length= 3 * 96)
# 7 save the model
model.save("/path/to/save/modelname")
# 8 load the model
loaded_model = load("/path/to/save/modelname")
2. PaddleBaseModel
PaddleBaseModel 是所有基于PaddlePaddle框架构建的时序模型的基类。 下方展示了一个简化版的 PaddleBaseModel 类声明, 此处略去了源代码中冗长的实现细节, 旨在于展示最重要的接口定义部分。 您可以参考文档 PaddleBaseModel API 获取完整代码。
2.1. 构造方法
import abc
from paddlets.models.base import BaseModel
class PaddleBaseModel(BaseModel, metaclass=abc.ABCMeta):
def __init__(
self,
in_chunk_len: int,
out_chunk_len: int,
skip_chunk_len: int = 0
):
super(PaddleBaseModel, self).__init__(
in_chunk_len=in_chunk_len,
out_chunk_len=out_chunk_len,
skip_chunk_len=skip_chunk_len
)
# other details are skipped
构造方法接收2个必需参数和1个可选参数:
in_chunk_len:历史窗口的大小。即:提供给模型用于训练的时间步数。
out_chunk_len:预测范围的大小。即:模型输出的时间步数。
skip_chunk_len: 在单条样本中,夹在 in_chunk 和 out_chunk 之间的时间块的长度。 需要注意的是 skip_chunk_len 既不用做样本的特征(即 X),也不用做样本的标签(即 Y)。默认情况下不会跳过任何一个时间步。
下方的图1通过一个具体的例子,进一步解释了上面提到的概念。
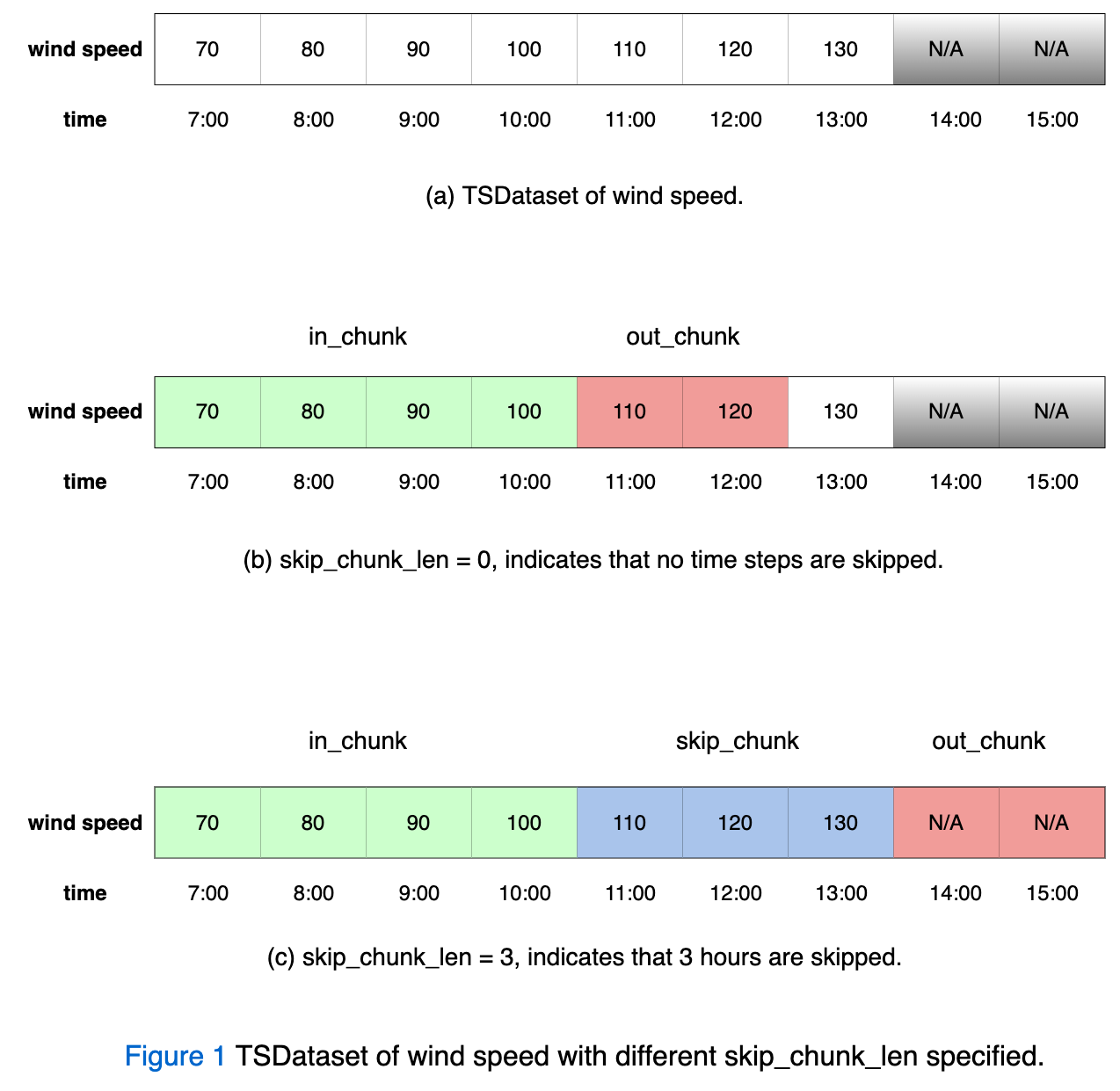
图 1(a)定义了一个包含风速的数据集,该数据集的采样频率为小时级。它一共包含从7:00到13:00这7个小时的风速数据。请注意,这份数据集并不包括图中灰色阴影标识的 14:00 - 15:00 这段时间的风速数据。
图 1(b)设置了 in_chunk_len = 4, skip_chunk_len = 0, out_chunk_len = 2, 则说明有以下描述成立:
一个长度为4小时的,开始于7:00的连续数据块,即 [70, 80, 90, 100],将被视为 in_chunk。
一个长度为2小时的,紧跟在 in_chunk 后面,开始于11:00的连续数据块,即 [110, 120],将被视为 out_chunk。
由于 skip_chunk_len 等于 0,所以在in_chunk和out_chunk之间没有任何时间点被跳过。
图1(b)和图1(c)中的 in_chunk_len 和 out_chunk_len 的值完全相同,唯一的区别是 skip_chunk_len 不同。具体来说,图1(c)中设置了 in_chunk_len = 4, skip_chunk_len = 3, out_chunk_len = 2, 则说明有以下描述成立:
一个长度为4小时的,开始于7:00的连续数据块,即 [70, 80, 90, 100],将被视为 in_chunk。
一个长度为3小时的,紧跟在 in_chunk 后面,开始于11:00的连续数据块,即 [110, 120, 130],将被跳过。
一个长度为2小时的,紧跟在 skip_chunk 后面,开始于14:00的连续数据块,即 [140, 150],将被视为 out_chunk。
总结以上例子,即,当前模型会使用过去4小时的风速去预测未来2小时的风速。同时,如果希望在in_chunk和out_chunk之间跳过几个小时的话,可以通过将可选参数 skip_chunk_len 设置为一个正整数来实现。
2.2. 训练
在PaddleTS中,所有的时序模型具有相同的训练接口。
为了让用户可以更多地关注上层视角,fit 方法不再接收一个类似于数组的特征矩阵,而是接收一个TSDataset数据集作为训练集参数, 从而完成了对基于数据集拆分样本集合的细节的封装。
下面展示了简化版的fit方法:
import abc
from typing import Optional
from paddlets.models.base import BaseModel
from paddlets import TSDataset
class PaddleBaseModel(BaseModel, metaclass=abc.ABCMeta):
# other contents are skipped.
def fit(
self,
train_data: TSDataset,
valid_data: Optional[TSDataset] = None
):
pass
参考以下图2作为进一步解释说明:

在该示例中,fit方法接收如图中灰色高亮部分所示的TSDataset数据集作为训练集参数, 并且在内部完成了数据集的拆分和样本集的构建(如上图中红色高亮部分所示)。
2.3. 预测
所有模型均拥有一致的预测接口。它接收一个同时包含 past target 和相关协变量的 TSDataset 数据集参数,并基于数据集的 past target 完成预测,返回一个新构建的 TSDataset 作为预测结果。返回的TSDataset数据集包含一个 future target 时序数据块,其长度等于 out_chunk_len。
对于该接口,有以下几点值得注意:
当前方法的TSDataset入参中仅包含过去的观测target和一些相关的协变量,并不包括未来的target。
预测方法仅会从给定的数据集参数中构建一条样本。
对于单次 predict 方法的调用,预测得到的结果的长度等于out_chunk_len的值。
下方展示了简化版的 predict 方法:
import abc
from paddlets.models.base import BaseModel
from paddlets import TSDataset
class PaddleBaseModel(BaseModel, metaclass=abc.ABCMeta):
# other contents are skipped.
def predict(self, data: TSDataset) -> TSDataset:
pass
我们用一个具体示例进一步对其说明。假设我们有一个如下图3所示的TSDataset数据集:
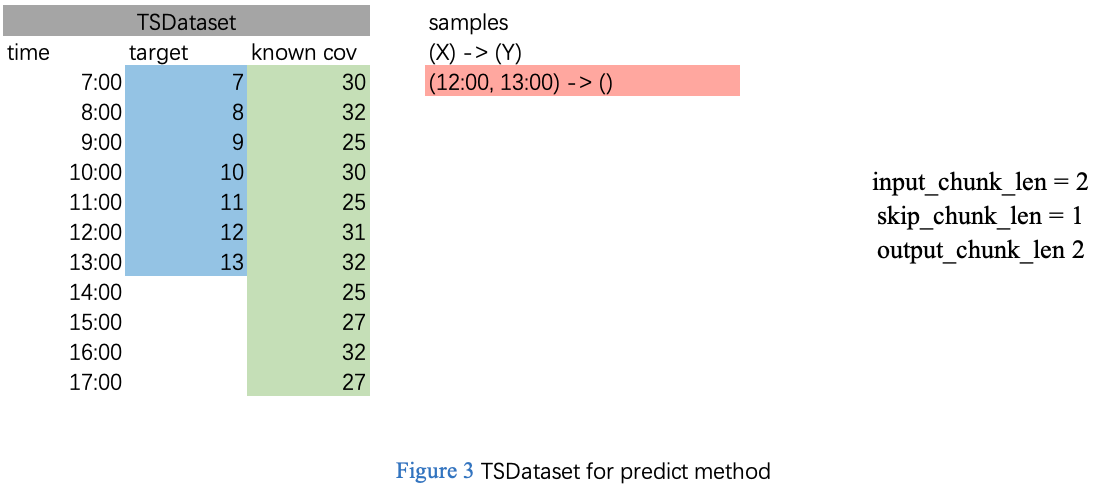
给定 in_chunk_len = 2, out_chunk_len = 2, skip_chunk_len = 1, 则以下叙述成立:
在 7:00 到 13:00 之间的数据都将被视为过去的target数据。
由于每次predict调用中都只会有一条样本被构建,同时,已知in_chunk_len = 2, skip_chunk_len = 1, out_chunk_len = 2, 则在 12:00 到 13:00 之间的数据会被送入当前已训练完成的模型,用于预测未来 15:00 到 16:00 之间的未来数据, 其中14:00点的数据会被跳过。
2.4. 递归多步预测
所有模型均拥有一致的递归多步预测接口。递归多步预测的策略是:一步步利用 model.predict 方法实现多步时序预测。当前时刻的预测结果会被添加至 TSDataset 时序数据集的目标列中,并在模型预测时,被添加至历史目标值的滑动窗口中用于下一时刻预测。
注意:每次调用 model.predict 的输出长度为 out_chunk_len, 所以 model.predict 会被调用 ceiling(predict_length/out_chunk_len) 次,以满足多步时序的输出长度需求。
例如,上述例子中的 Model 的 out_chunk_length 是 96 ,而 model.recursive_predict 允许你将 predict_length 设置为 3 * 96 或者更多。
# 6 recursive predict
recursive_predicted_dataset = model.recursive_predict(data, predict_length= 3 * 96)
注意: model.recursive_predict 函数在 model.skip_chunk != 0 时,无法使用。
更多使用细节,请参考:API: BaseModel.recursive_predict
对于PaddleTS提供的与预测相关的 Backtest 回测能力,请参考:API: Backtest
2.5. 模型持久化
模型训练完成后,我们仍需提供一种将训练完成的模型持久化的方法,以便在未来希望使用该模型时无需对其重复训练。同时,我们也提供一个统一的方法,用于加载一个已经被保存在硬盘上的PaddleBaseModel模型。
以下的代码示例展示了如何持久化保存一个 PaddleBaseModel 模型。请注意,同一个模型可以被保存多次。
from paddlets import TSDataset
from paddlets.models.forecasting import RNNBlockRegressor
# Prepare a fitted model
training_data = TSDataset.load_from_csv("/path/to/csv")
model = RNNBlockRegressor(in_chunk_len=96, out_chunk_len=96)
model.fit(train_tsdataset=training_data)
# save the model for multiple times.
model.save("/path/to/save/modelname_1")
model.save("/path/to/save/modelname_2")
在模型保存完成的一段时间之后,您可以通过以下方式加载模型:
from paddlets.models.model_loader import load
loaded_rnn_reg_1 = load("/path/to/save/modelname_1")
loaded_rnn_reg_2 = load("/path/to/save/modelname_2")