开始使用PaddleTS
1. 安装PaddleTS
PaddlePaddle ,可跳过此步骤。PaddleTS 。pip install paddlets
除此之外,我们也可以通过以下pip命令同时安装 PaddlePaddle 和 PaddleTS 。
pip install paddlets[all]
安装成功后,就可以import PaddleTS并且使用了。
import paddlets
print(paddlets.__version__)
2. 构建TSDataset
TSDataset 是 PaddleTS 中最主要的类之一,其被设计用来表示绝大多数时序样本数据。通常,时序数据可以分为以下几种:
单变量数据,只包含单列的预测目标,同时可以包涵单列或者多列协变量
多变量数据,包涵多列预测目标,同时可以包涵单列或者多列协变量
TSDataset 需要包含time_index属性,time_index支持 pandas.DatetimeIndex 和 pandas.RangeIndex 两种类型。2.1. 内置TSDataset数据集
PaddleTS内集成了部分公开数据集,便于用户使用;基于内置数据集,我们可以轻松的完成TSDataset的构建。
from paddlets.datasets.repository import get_dataset, dataset_list
print(f"built-in datasets: {dataset_list()}")
#built-in datasets: ['UNI_WTH', 'ETTh1', 'ETTm1', 'ECL', 'WTH']
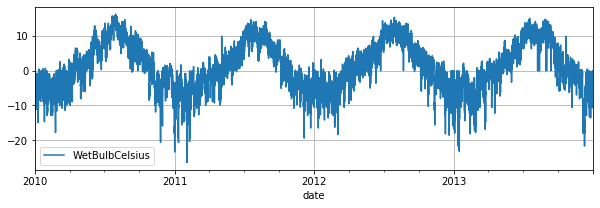
通过调用 get_dataset 函数可以导入指定的内置数据集,并返回TSDataset对象。示例数据集是一份包含了2010年–2014年的关于天气的单变量数据,其中 WetBulbCelsuis 代表湿球温度。
dataset = get_dataset('UNI_WTH')
print(type(dataset))
#<class 'paddlets.datasets.tsdataset.TSDataset'>
dataset.plot()
2.2. 构建自定义数据集
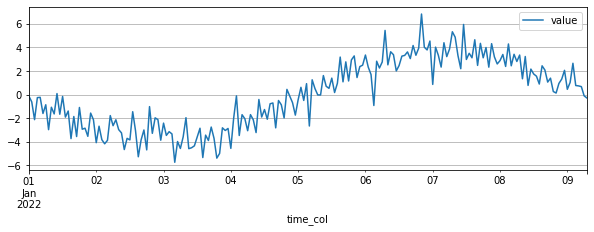
用户可以基于 pandas.DataFrame 或者CSV文件去构建TSDataset。
import pandas as pd
import numpy as np
from paddlets import TSDataset
x = np.linspace(-np.pi, np.pi, 200)
sinx = np.sin(x) * 4 + np.random.randn(200)
df = pd.DataFrame(
{
'time_col': pd.date_range('2022-01-01', periods=200, freq='1h'),
'value': sinx
}
)
custom_dataset = TSDataset.load_from_dataframe(
df, #Also can be path to the CSV file
time_col='time_col',
target_cols='value',
freq='1h'
)
custom_dataset.plot()
TSDataset 模块功能,可参考 数据集定义、加载以及操作3. 数据查看与分析
通过调用 TSDataset.summary 方法即可实现对数据统计信息的查看。
dataset.summary()
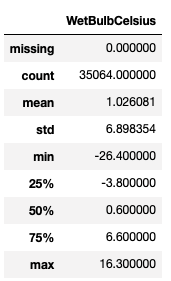
missing 变量用于表示数据的缺失值比例,我们多数深度模型要求数据不能有缺失值,因此如果不为零,数据在入模前需要进行缺失值填充以及处理。FFT 算子进行数据频域属性分析。#FFT
from paddlets.analysis import FFT
fft = FFT()
res = fft(dataset, columns='WetBulbCelsius')
fft.plot()
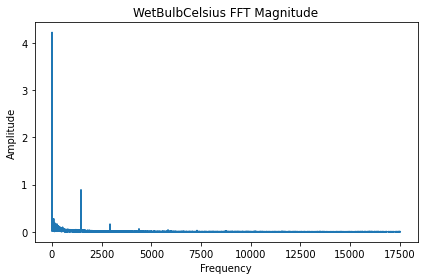
FFT 模块功能,可参考 Analysis4. 模型训练及预测
这里提供了一个如何基于时序数据去构建深度神经网络模型的例子,包括模型的训练以及预测。
4.1. 构建训练、验证以及测试数据集
train_dataset, val_test_dataset = dataset.split(0.7)
val_dataset, test_dataset = val_test_dataset.split(0.5)
train_dataset.plot(add_data=[val_dataset,test_dataset], labels=['Val', 'Test'])
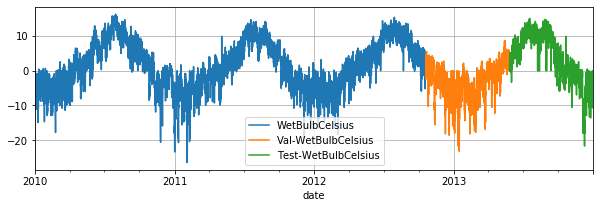
4.2. 模型训练
in_chunk_len: 输入时序窗口的大小,代表每次训练以及预测时候输入到模型中的前序的时间步长。out_chunk_len: 输出时序窗口的大小,代表每次训练以及预测时候输出的后续的时间步长。
MLPRegressor 模型的初始化,如 max_epochs , optimizer_params 等。from paddlets.models.forecasting import MLPRegressor
mlp = MLPRegressor(
in_chunk_len = 7 * 24,
out_chunk_len = 24,
max_epochs=100
)
现在,我们可以使用 train_dataset 和 val_dataset 对初始化好的模型进行训练,其中 val_dataset 是可选的。
mlp.fit(train_dataset, val_dataset)
MLPRegressor 模块功能,可参考 Models4.3. 模型预测
接下来,我们用已经训练好的模型进行预测,输出的预测结果类型是TSDataset, 同时其长度等于 out_chunk_len 。
subset_test_pred_dataset = mlp.predict(val_dataset)
subset_test_pred_dataset.plot()
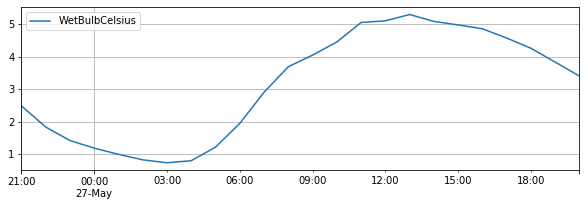
我们截取测试集中对应的真实数据,和我们的预测结果进行对比,结果如下:
subset_test_dataset, _ = test_dataset.split(len(subset_test_pred_dataset.target))
subset_test_dataset.plot(add_data=subset_test_pred_dataset, labels=['Pred'])
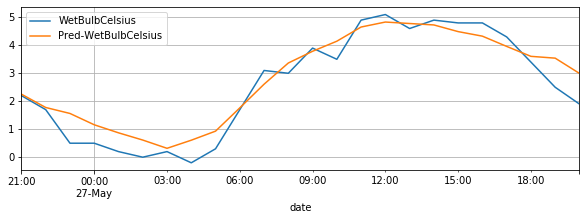
如果我们想要预测的长度大于模型初始化时候指定的 out_chunk_len 长度,我们可以通过调用 recursive_predict 接口来实现。其支持指定想要输出的预测长度;如上述的 UNI_WTH 数据集,我们想要预测未来96个小时的 WetBulbCelsuis , 我们可以通过调用 recursive_predict 通过如下方法实现:
subset_test_pred_dataset = mlp.recursive_predict(val_dataset, 24 * 4)
subset_test_dataset, _ = test_dataset.split(len(subset_test_pred_dataset.target))
subset_test_dataset.plot(add_data=subset_test_pred_dataset, labels=['Pred'])
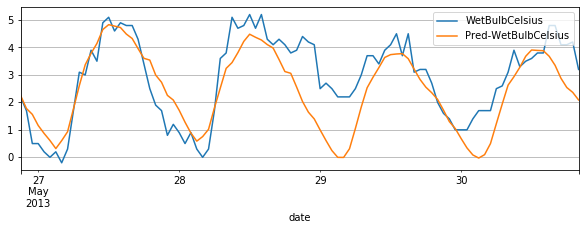
5. 评估和回测
现在,我们有了预测数据和真实数据,可以计算相应的metrics指标。
from paddlets.metrics import MAE
mae = MAE()
mae(subset_test_dataset, subset_test_pred_dataset)
#{'WetBulbCelsius': 0.6734366664042076}
上面,我们只计算了测试集中部分数据的metrics指标,我们可以通过 backtest 实现对整个测试集的metrics指标计算。
from paddlets.utils import backtest
metrics_score = backtest(
data=val_test_dataset,
model=mlp,
start=0.5,
predict_window=24,
stride=24,
metric=mae
)
print(f"mae: {metrics_score}")
#mae: 1.3767653357878213
backtest 模块功能,可参考 回测6. 协变量
PaddleTS 同样支持协变量数据的构建以及入模训练,用于提供除target外的额外信息,帮助我们提高时序模型效果。known_covariate(已知协变量),指可在预测未来时间已知的变量,例如天气预报observed_covariate(观测协变量),指只能在历史中观察到的变量数据,例如测量的温度static_covariate(静态协变量),指整个时间范围内保持不变的变量,在多数序组合预测中会使用
6.1. 自动构建日期相关协变量
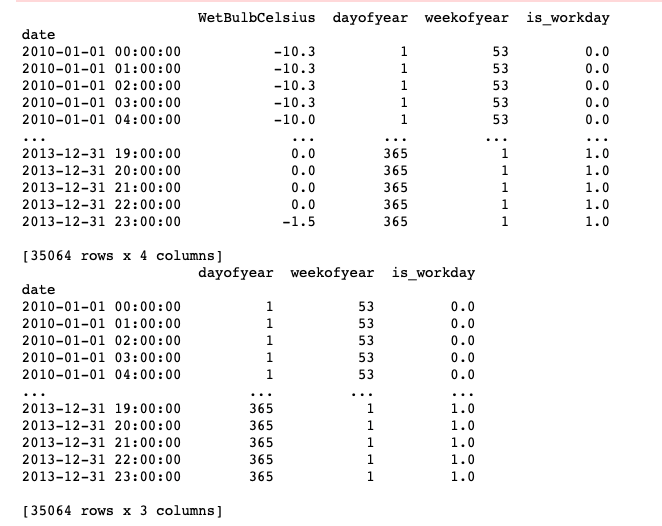
我们可以使用 paddlets.transform 中的 TimeFeatureGenerator 去自动生成日期与时间相关的协变量。如是否节假日,当前是每年的第几周等信息,因为这些信息在预测未来数据的时候也是已知的,因此其属于 known_covariate(已知协变量)。 在以下示例中,我们会生成三个时间相关的协变量,分别代表 一年中的第几天 、一周中的第几天、 是否是工作日 。
from paddlets.transform import TimeFeatureGenerator
time_feature_generator = TimeFeatureGenerator(feature_cols=['dayofyear', 'weekofyear', 'is_workday'])
dataset_gen_target_cov = time_feature_generator.fit_transform(dataset)
print(dataset_gen_target_cov)
print(dataset_gen_target_cov.known_cov)
6.2. 自定义协变量
我们也可以基于 pandas.DataFrame 或者CSV文件去构建一个只包含协变量的 TSDataset 。
import pandas as pd
from paddlets import TSDataset
df = pd.DataFrame(
{
'time_col': pd.date_range(
dataset.target.time_index[0],
periods=len(dataset.target),
freq=dataset.freq
),
'cov1': [i for i in range(len(dataset.target))]
}
)
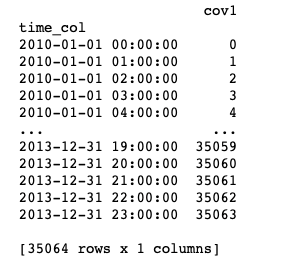
dataset_cus_cov = TSDataset.load_from_dataframe(
df,
time_col='time_col',
known_cov_cols='cov1',
freq=dataset.freq
)
print(dataset_cus_cov)
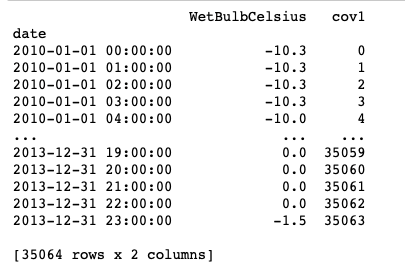
接下来,我们可以将新构建只包含协变量的TSDataset和原有只包含target信息的TSDataset进行聚合。
dataset_cus_target_cov = TSDataset.concat([dataset, dataset_cus_cov])
print(dataset_cus_target_cov)
7. 基于包含协变量数据的模型训练
基于前面构建好的包含协变量的数据,接下来,我们去训练一个 RNNBlockRegressor 模型作为一个例子。
from paddlets.models.forecasting import RNNBlockRegressor
rnn_reg = RNNBlockRegressor(
in_chunk_len = 7 * 24,
out_chunk_len = 24,
skip_chunk_len = 0,
sampling_stride = 24,
max_epochs = 100
)
构建训练、验证以及测试数据集
train_dataset, val_test_dataset = dataset_gen_target_cov.split(0.8)
val_dataset, test_dataset = val_test_dataset.split(0.5)
通过 paddlets.transform 的 StandardScaler 对数据进行归一化。
from paddlets.transform import StandardScaler
scaler = StandardScaler()
scaler.fit(train_dataset)
train_dataset_scaled = scaler.transform(train_dataset)
val_test_dataset_scaled = scaler.transform(val_test_dataset)
val_dataset_scaled = scaler.transform(val_dataset)
test_dataset_scaled = scaler.transform(test_dataset)
现在我们可以训练模型并对模型效果进行评估。
rnn_reg.fit(train_dataset_scaled, val_dataset_scaled)
from paddlets.utils import backtest
metrics_score = backtest(
data=val_test_dataset_scaled,
model=rnn_reg,
start=0.5,
predict_window=24,
stride=24,
metric=mae
)
print(f"mae: {metrics_score}")
#mae: 0.3021404146482557
8. Pipeline
现在,我们可以通过Pipeline的方法,将上述提到的数据处理流程整合到一起,提供一个端到端的数据建模解决方案:
from paddlets.pipeline import Pipeline
train_dataset, val_test_dataset = dataset.split(0.8)
val_dataset, test_dataset = val_test_dataset.split(0.5)
我们通过添加时间相关的特征生成模块、数据归一化模块以及模型训练模块去初始化一个Pipeline对象。
pipe = Pipeline([
(TimeFeatureGenerator, {"feature_cols": ['dayofyear', 'weekofyear', 'is_workday'], "extend_points": 24}),
(StandardScaler, {}),
(RNNBlockRegressor, {
"in_chunk_len": 7 * 24,
"out_chunk_len": 24,
"skip_chunk_len": 0,
"sampling_stride": 24,
"max_epochs": 100
})
])
接下来,我们可以对Pipeline整体进行训练以及效果评估,Pipeline会自动按序调用内部的模块进行数据的处理以及模型训练。
pipe.fit(train_dataset, val_dataset)
from paddlets.utils import backtest
metrics_score = backtest(
data=val_test_dataset,
model=pipe,
start=0.5,
predict_window=24,
stride=24,
metric=mae
)
print(f"mae: {metrics_score}")
#mae: 4.992150762390378
Pipeline 模块功能,可参考 Pipeline9. AutoTS
AutoTS是用于支持PaddleTS的自动机器学习能力组件。
AutoTS 可以支持 PaddleTS 模型和 pipeline 的自动超参数选择,减少人工介入成本,降低专业门槛。
from paddlets.automl.autots import AutoTS
from paddlets.models.forecasting import MLPRegressor
from paddlets.datasets.repository import get_dataset
tsdataset = get_dataset("UNI_WTH")
下面,我们利用 MLPRegressor 初始化了一个 AutoTS 模型,其中它的 in_chunk_len 是96,out_chunk_len 是2。
autots_model = AutoTS(MLPRegressor, 96, 2)
接下来我们可以像应用一个普通的 PaddleTS 模型一样训练这个模型,并将其用于预测。
AutoTS 为 PaddleTS 模型内置了一套推荐的默认检索空间,所以这个 MLPRegressor 在默认的检索空间下面进行超参优化,并利用所发现的最优参数拟合这个 MLPRegressor。
autots_model.fit(tsdataset)
predicted_tsdataset = autots_model.predict(tsdataset)
AutoTS 也允许我们获取超参优化过程中所找到的最优的参数
best_param = autots_model.best_param
AutoTS 模块功能,可参考 AutoTS