集成预测器
集成模型是用集成学习的思想去把多个PaddleTS的预测器集合成一个预测器。目前我们支持两种集成预测器StackingEnsembleForecaster 和 WeightingEnsembleForecaster
1.准备数据
1.1. 获取数据
获取PaddleTS内置数据集
from paddlets.datasets.repository import get_dataset
tsdataset = get_dataset("WTH")
1.2. 分割数据
分割数据成训练集/测试集/验证集
ts_train, ts_val_test = tsdataset.split("2012-03-31 23:00:00")
ts_val, ts_test = ts_val_test.split("2013-02-28 23:00:00")
1.3. 数据预处理(可选)
用StandardScaler去归一化数据(可选)
from paddlets.transform.sklearn_transforms import StandardScaler
scaler = StandardScaler()
scaler.fit(ts_train)
ts_train = scaler.transform(ts_train)
ts_val = scaler.transform(ts_val)
ts_test = scaler.transform(ts_test)
ts_val_test = scaler.transform(ts_val_test)
2. 准备模型
准备集成预测器需要的底层模型
请注意,为了保持模型预测的一致性, in_chunk_len, out_chun_len, skip_chunk_len 这三个参数已经被提取到集成模型中,您可以在base模型的参数中忽略这三个参数。
from paddlets.models.forecasting import MLPRegressor
from paddlets.models.forecasting import NHiTSModel
from paddlets.models.forecasting import RNNBlockRegressor
nhits_params = {
'sampling_stride': 24,
'eval_metrics':["mse", "mae"],
'batch_size': 32,
'max_epochs': 10,
'patience': 100
}
rnn_params = {
'sampling_stride': 24,
'eval_metrics': ["mse", "mae"],
'batch_size': 32,
'max_epochs': 10,
'patience': 100,
}
mlp_params = {
'sampling_stride': 24,
'eval_metrics': ["mse", "mae"],
'batch_size': 32,
'max_epochs': 10,
'patience': 100,
'use_bn': True,
}
3. 组装和拟合模型
组装和拟合模型,WeightingEnsembleForecaster 或者 StackingEnsembleForecaster.
3.1. 组装和拟合WeightingEnsembleForecaster
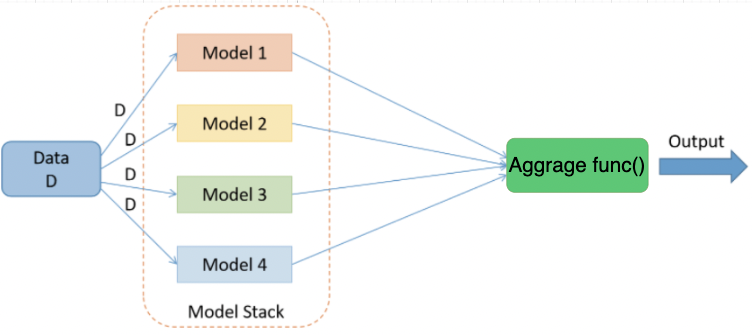
WeightingEnsembleForecaster 使用聚合函数来聚合基础模型预测,默认使用“均值”模式。有关 WeightingEnsembleForecaster 的更多信息,请阅读 WeightingEnsembleForecaster doc .
例子1
使用默认模式(均值模式)
from paddlets.ensemble import WeightingEnsembleForecaster
reg = WeightingEnsembleForecaster(
in_chunk_len=7 * 24,
out_chunk_len=24,
skip_chunk_len=0,
estimators=[(NHiTSModel, nhits_params),(RNNBlockRegressor, rnn_params), (MLPRegressor, mlp_params)])
reg.fit(ts_train, ts_val)
例子2
使用自选模式
from paddlets.ensemble import WeightingEnsembleForecaster
#get mode list
WeightingEnsembleForecaster.get_support_modes()
#Supported ensemble modes:['mean', 'min', 'max', 'median']
#select mode
reg = WeightingEnsembleForecaster(
in_chunk_len=7 * 24,
out_chunk_len=24,
skip_chunk_len=0,
estimators=[(NHiTSModel, nhits_params),(RNNBlockRegressor, rnn_params), (MLPRegressor, mlp_params)],
mode = "min")
reg.fit(ts_train, ts_val)
3.2. 组装和拟合StackingEnsembleForecaster
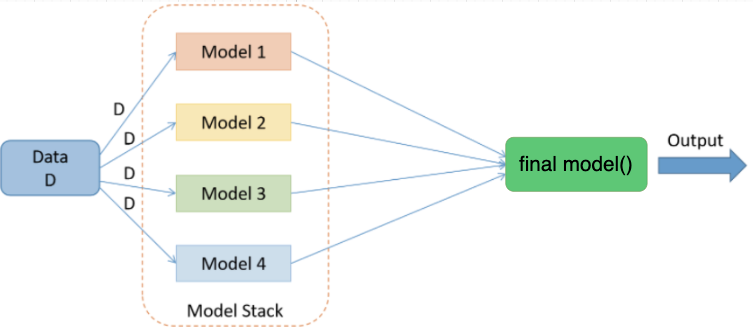
StackingEnsembleForecaster 使用最终学习器来拟合基本模型预测,默认使用 GradientBoostingRegressor(max_depth=5)。经过我们验证,stacking ensemble 在很多情况下都能取得比底层模型更好的结果。有关 StackingEnsembleForecaster 的更多信息,请阅读 StackingEnsembleForecaster doc .
例子1
使用默认模式(第二层学习器为 GradientBoostingRegressor(max_depth=5))
from paddlets.ensemble import StackingEnsembleForecaster
reg = StackingEnsembleForecaster(
in_chunk_len=7 * 24,
out_chunk_len=24,
skip_chunk_len=0,
estimators=[(NHiTSModel, nhits_params),(RNNBlockRegressor, rnn_params), (MLPRegressor, mlp_params)])
reg.fit(ts_train, ts_val)
例子2
使用自定义学习器(目前只支持sklearn库的regressor)
from sklearn.linear_model import Ridge
from paddlets.ensemble import StackingEnsembleForecaster
reg = StackingEnsembleForecaster(
in_chunk_len=7 * 24,
out_chunk_len=24,
skip_chunk_len=0,
estimators=[(NHiTSModel, nhits_params),(RNNBlockRegressor, rnn_params), (MLPRegressor, mlp_params)],
final_learner=Ridge(alpha=0.5))
reg.fit(ts_train, ts_val)
4. 用集成模型进行回测
from paddlets.utils import backtest
from paddlets.metrics import MAE
mae, ts_pred = backtest(data=ts_val_test,
model=reg,
start="2013-03-01 00:00:00", # the point after "start" as the first point
metric=MAE(),
predict_window=24,
stride=24,
return_predicts=True
)