数据集定义, 加载以及操作
TSDataset
TSDataset 是 PaddleTS 中一个主要的类结构,用于表示绝大多数的时序样本数据,并作为PaddleTS其他算子的输入以及输出对象。TSDataset 包涵两类时序数据:
待预测目标:表示希望被预测的时序序列
协变量:无需被预测的时间序列,协变量的加入通常用于辅助提高模型预测的效果
TSDataset支持的时序样本数据可以分为:
单变量数据,只包含单列的预测目标,同时可以包涵单列或者多列协变量
多变量数据,包涵多列预测目标,同时可以包涵单列或者多列协变量
我们将非预测目标变量定义为协变量,在时序数据中,协变量可分为以下三种:
- 观测协变量 (observed_cov):
指只能在历史中观察到的变量数据,例如测量的温度
- 可预知协变量 (known_cov):
指可在预测未来时间已知的变量,例如天气预报
- 静态协变量 (static_cov):
指整个时间范围内保持不变的变量
一个 TSDataset 对象由一个或者多个 TimeSeries 对象构成,每个 TimeSeries 可分别代表target(待预测目标), observed_covariate(观测协变量)以及known_covariate(可预知协变量)。
TimeSeries
TimeSeries 是用于表示时序数据的最小粒度;可以分别代表target, observed_covariate 或者known_covariate 其中一种类型。TimeSeries本身可以是单变量或者多变量。
TimeSeries 需要转换成 TSDataset 对象才能在 PaddleTS 中使用
使用示例
构建TSDataset
基于 pandas.DataFrame 或者CSV文件构建一个只包含 tareget 序列的TSDataset:
import pandas as pd
import numpy as np
from paddlets import TSDataset
x = np.linspace(-np.pi, np.pi, 200)
sinx = np.sin(x) * 4 + np.random.randn(200)
df = pd.DataFrame(
{
'time_col': pd.date_range('2022-01-01', periods=200, freq='1h'),
'value': sinx
}
)
target_dataset = TSDataset.load_from_dataframe(
df, #Also can be path to the CSV file
time_col='time_col',
target_cols='value',
freq='1h'
)
target_dataset.plot()
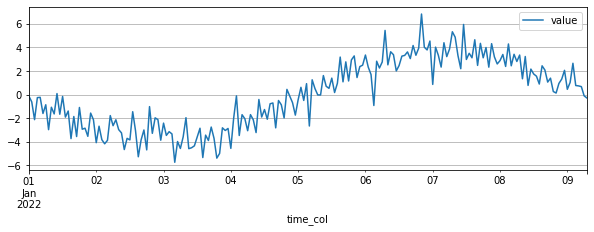
构建一个既包含target序列,也包含协变量序列的TSDataset:
方法1:
import pandas as pd
from paddlets import TSDataset
df = pd.DataFrame(
{
'time_col': pd.date_range('2022-01-01', periods=200, freq='1h'),
'value': sinx,
'known_cov_1': sinx + 4,
'known_cov_2': sinx + 5,
'observed_cov': sinx + 8,
'static_cov': [1 for i in range(200)],
}
)
target_cov_dataset = TSDataset.load_from_dataframe(
df,
time_col='time_col',
target_cols='value',
known_cov_cols=['known_cov_1', 'known_cov_2'],
observed_cov_cols='observed_cov',
static_cov_cols='static_cov',
freq='1h'
)
target_cov_dataset.plot(['value', 'known_cov_1', 'known_cov_2', 'observed_cov'])
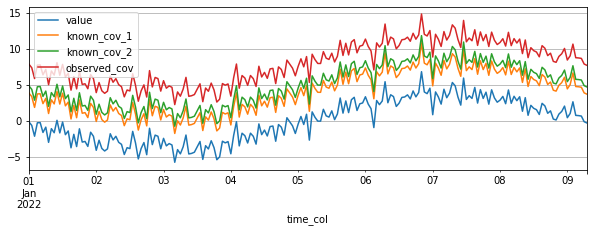
方法2:
import pandas as pd
from paddlets import TSDataset
x_l = np.linspace(-np.pi, np.pi, 300)
sinx_l = np.sin(x_l) * 4 + np.random.randn(300)
df = pd.DataFrame(
{
'time_col': pd.date_range('2022-01-01', periods=300, freq='1h'),
'known_cov_1': sinx_l + 4,
'known_cov_2': sinx_l + 5
}
)
known_cov_dataset = TSDataset.load_from_dataframe(
df,
time_col='time_col',
known_cov_cols=['known_cov_1', 'known_cov_2'],
freq='1h'
)
df = pd.DataFrame(
{
'time_col': pd.date_range('2022-01-01', periods=200, freq='1h'),
'observed_cov': sinx + 8
}
)
observed_cov_dataset = TSDataset.load_from_dataframe(
df,
time_col='time_col',
observed_cov_cols='observed_cov',
freq='1h'
)
target_cov_dataset = TSDataset.concat([target_dataset, known_cov_dataset, observed_cov_dataset])
target_cov_dataset.plot(['value', 'known_cov_1', 'known_cov_2', 'observed_cov'])
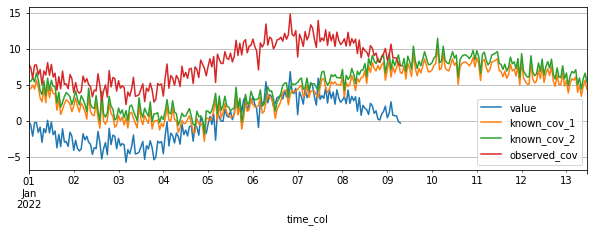
方法3:
import pandas as pd
from paddlets import TSDataset
from paddlets import TimeSeries
df = pd.DataFrame(
{
'time_col': pd.date_range('2022-01-01', periods=300, freq='1h'),
'known_cov_1': sinx_l + 4,
'known_cov_2': sinx_l + 5,
}
)
known_cov_dataset = TimeSeries.load_from_dataframe(
df,
time_col='time_col',
value_cols=['known_cov_1', 'known_cov_2'],
freq='1h'
)
df = pd.DataFrame(
{
'time_col': pd.date_range('2022-01-01', periods=200, freq='1h'),
'observed_cov': sinx + 8
}
)
observed_cov_dataset = TimeSeries.load_from_dataframe(
df,
time_col='time_col',
value_cols='observed_cov',
freq='1h'
)
target_cov_dataset = target_dataset.copy()
target_cov_dataset.known_cov = known_cov_dataset
target_cov_dataset.observed_cov = observed_cov_dataset
target_cov_dataset.plot(['value', 'known_cov_1', 'known_cov_2', 'observed_cov'])
如果提供的原始样本数据存在缺失值,我们可以通过TSDataset构建时的自动填充功能实现缺失值的填充,目前支持7种填充方式。
import pandas as pd
import numpy as np
from paddlets import TSDataset
df = pd.DataFrame(
{
'time_col': pd.date_range('2022-01-01', periods=200, freq='1h'),
'value': sinx,
'known_cov_1': sinx + 4,
'known_cov_2': sinx + 5,
'observed_cov': sinx + 8,
'static_cov': [1 for i in range(200)],
}
)
df.loc[1, 'value'] = np.nan
target_cov_dataset = TSDataset.load_from_dataframe(
df,
time_col='time_col',
target_cols='value',
known_cov_cols=['known_cov_1', 'known_cov_2'],
observed_cov_cols='observed_cov',
static_cov_cols='static_cov',
freq='1h',
fill_missing_dates=True,
fillna_method='pre' #max, min, avg, median, pre, back, zero
)
print(target_cov_dataset['value'][1])
#0.0
数据查看与分析
数据画图展示
target_cov_dataset.plot(['value'])
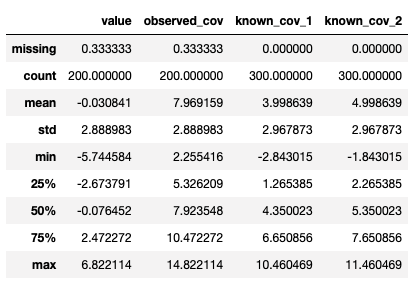
通过调用 TSDataset.summary 方法即可实现对数据统计信息的查看。
target_cov_dataset.summary()
构建训练、验证以及测试数据集
train_dataset, val_test_dataset = target_cov_dataset.split(0.8)
val_dataset, test_dataset = val_test_dataset.split(0.5)
train_dataset.plot(add_data=[val_dataset,test_dataset])
增加列
train_dataset
new_line = pd.Series(
np.array(range(200)),
index=pd.date_range('2022-01-01', periods=200, freq='1D')
)
## option 1:
## The name of new column which need not to exists in TSDataset`s columns
## The type of value is pd.Series
## type represent the TimeSeries where to put the new column, konw_cov by default
## The index of value must be same as the index of the TSDataset object
target_cov_dataset.set_column(
column='new_b',
value=new_line,
type='observed_cov'
)
## option 2:
## The option is equal to option 1 which type is default
target_cov_dataset['new_b'] = new_line
更新列
## option 1:
## The name of new column which need to exists in TSDataset`s columns
## The type of value is pd.Series
## The index of value must be same as the index of the TSDataset object
target_cov_dataset.set_column(
column='observed_cov',
value=new_line
)
## Option 2:
## No different from option 1
target_cov_dataset['observed_cov'] = new_line
删除列
## Delete column
target_cov_dataset.drop('new_b')
## Delete columns
target_cov_dataset.drop(['known_cov_1', 'new_b'])
获取列
## Get column
column = target_cov_dataset['known_cov_2'] # The type of column is pd.Serie
## Get columns
columns = target_cov_dataset[['known_cov_2', 'observed_cov']] # The type of columns is pd.DataFrame
获取数据类型
dtypes = target_cov_dataset.dtypes
print(dtypes)
value int64
known_cov_1 int64
known_cov_2 int64
observed_cov int64
dtype: object
修改数据类型
target_cov_dataset.astype('float32')
dtypes = target_cov_dataset.dtypes
print(dtypes)
value float32
known_cov_1 float32
known_cov_2 float32
observed_cov float32
dtype: object
获取包含的列名信息
columns = target_cov_dataset.columns
print(columns)
#{'value': 'target', 'known_cov_1': 'known_cov', 'known_cov_2': 'known_cov', 'observed_cov': 'observed_cov'}