XAI
Xai是一个模型解释模块,可以解释复杂的模型预测结果是如何形成的,帮助用户快速理解输入输出之间的关系。 目前xai模块分为两个子模块:ante_hoc和post_hoc。 前者基于设计的模型网络结构提供可解释性,后者与模型网络无关,而是通过代理模型解释原始模型。
1. 准备数据
1.1 获取数据与导入库
获取PaddleTS内置数据集
import numpy as np
import pandas as pd
import paddle
import matplotlib.pyplot as plt
np.random.seed(123456)
paddle.seed(123456)
from paddlets import TSDataset, TimeSeries
from paddlets.xai.post_hoc.shap_explainer import ShapExplainer
from paddlets.datasets.repository import get_dataset
tsdataset = get_dataset("ECL")
1.2 划分数据
划分数据集为训练/测试/验证
ts_known = TimeSeries(data[['MT_001', ]], freq='1H').copy()
ts_cols = data.columns
keep_cols = ['MT_000', ]
remove_cols = []
for col, types in ts_cols.items():
if (types is 'target'):
continue
if (col not in keep_cols):
remove_cols.append(col)
data.drop(remove_cols)
data.set_known_cov(ts_known)
data, _ = data.split('2014-06-30')
train_data, test_data = data.split('2014-06-15')
train_data, val_data = train_data.split('2014-06-01')
2. 准备模型参数
准备基础模型参数
in_chunk_len = 24
out_chunk_len = 24
skip_chunk_len = 0
sampling_stride = 24
max_epochs = 10
patience = 5
3. 构建并训练
构建并训练pipeline
from paddlets.models.forecasting import NBEATSModel
from paddlets.transform import StandardScaler
from paddlets.pipeline.pipeline import Pipeline
pipeline_list = [(StandardScaler, {}),
(NBEATSModel, {'in_chunk_len': in_chunk_len,
'out_chunk_len': out_chunk_len,
'skip_chunk_len': skip_chunk_len,
'max_epochs': max_epochs,
'patience': patience})
]
pipe = Pipeline(pipeline_list)
pipe.fit(train_data, val_data)
4. 模型解释
基于kernel shap方法解释预测结果
4.1 初始化解释器
ShapExplainer: 帮助用户实现PaddleTS模型与shap解释器之间的链接桥梁,更好的帮助用户理解输出结果性质
se = ShapExplainer(pipe, train_data, background_sample_number=100, keep_index=True, use_paddleloader=False)
4.2 解释测试样本
ShapExplainer.explain: 帮助用户计算需要解释性的样本,给出特征贡献度
shap_value = se.explain(test_data_fea, nsamples=100)
4.3 特征贡献图
ShapExplainer.force_plot: 采用加性图层展示需要解释性的样本数据时间点。展示结果中lag_0代表in_chunk_len最后一个时刻,lag_1代表out_chunk_len的第一个时刻
se.force_plot(out_chunk_indice=[5, ], sample_index=0, contribution_threshold=0.05)

4.4 特征重要性展示
ShapExplainer.summary_plot: 针对指定的待预测时间点计算特征贡献度数值并排序
se.summary_plot(out_chunk_indice=[5, ], sample_index=0)
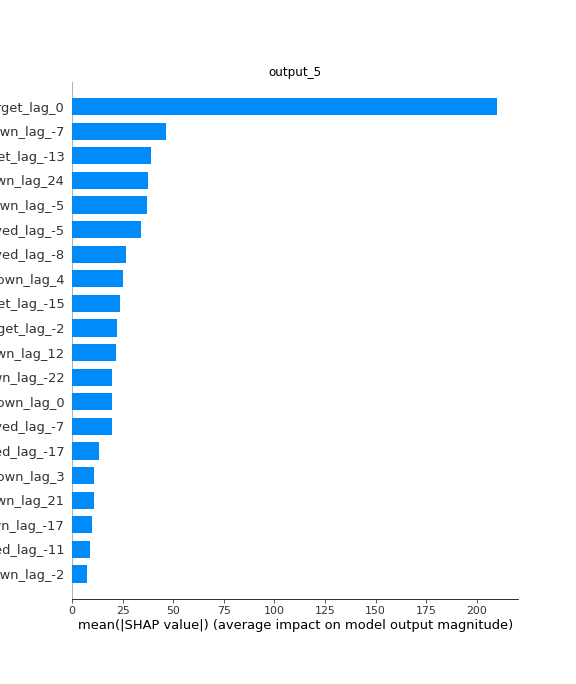
4.5 多维度输出贡献值展示—特征变量
Note: 以下展示每个特征变量在所有输入时间步和所有输出时间步上的特征贡献度
se.plot(method='V')
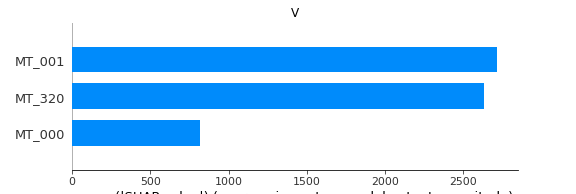
4.6 多维度输出贡献值展示—输入时间步
Note: 以下展示每个输入时间步在所有特征和所有输出时间步上的特征贡献度
se.plot(method='I')
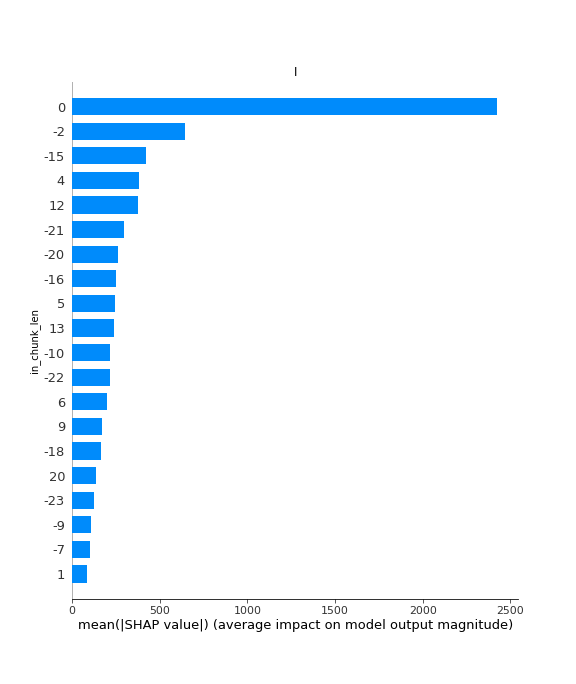
4.7 多维度输出贡献值展示—输入时间步与输出时间步
Note: 以下展示每个输入时间步和每个输出时间步在所有特征变量上的特征贡献度
se.plot(method='OI')
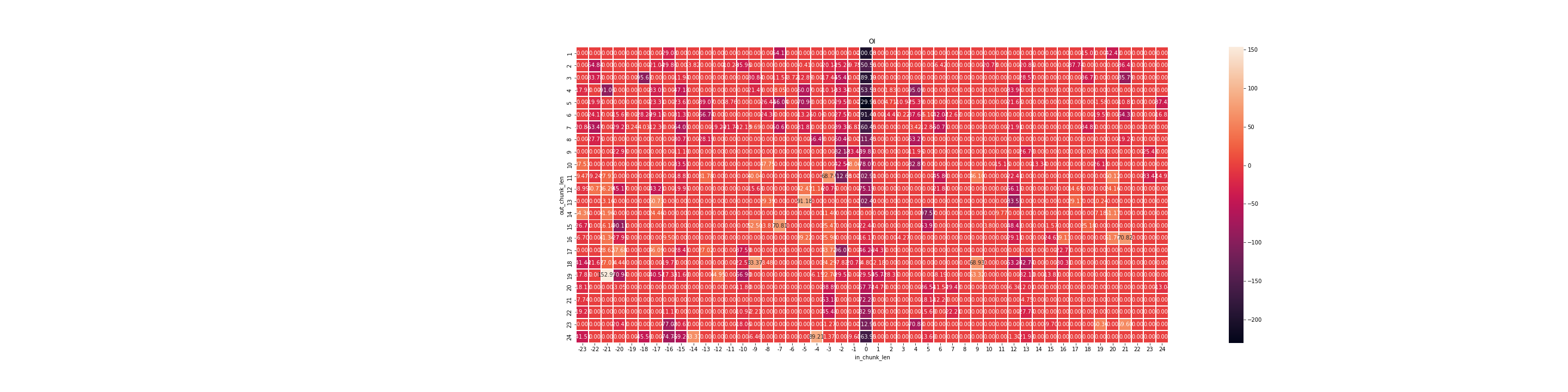
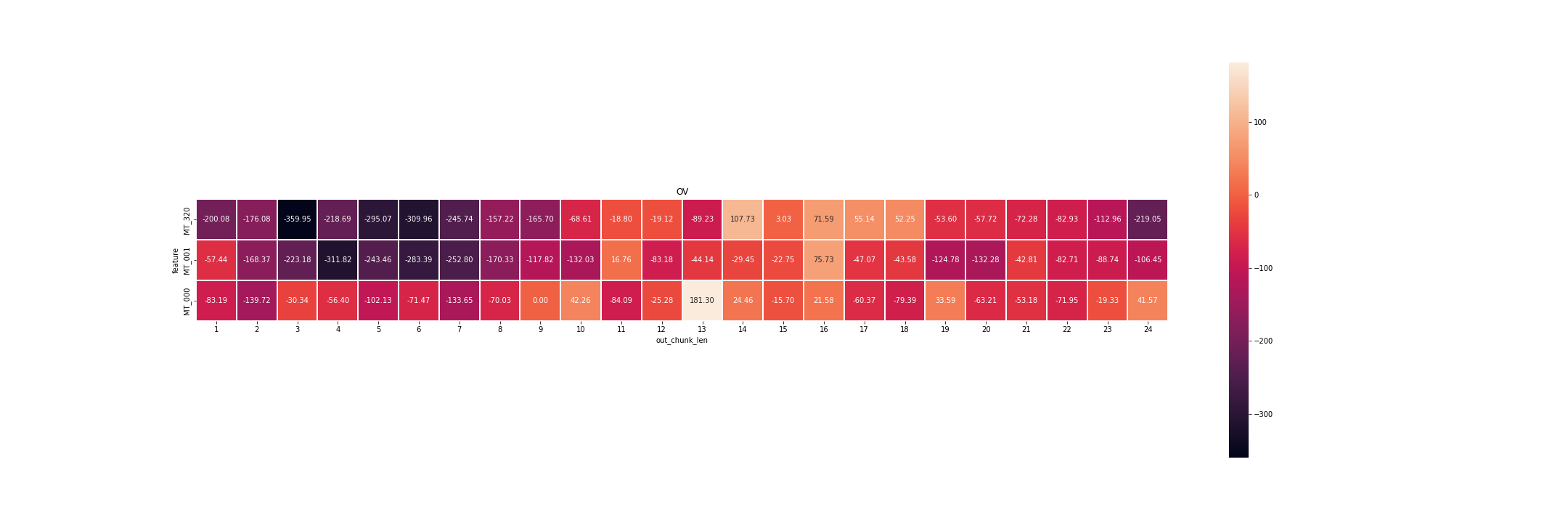
4.8 多维度输出贡献值展示—特征变量与输出时间步
Note: 以下展示每个特征变量和每个输出时间步在所有输入时间步上的特征贡献度
se.plot(method='OV')
4.9 多维度输出贡献值展示—特征变量和输入时间步
Note: 以下展示每个输入时间步和每个变量在所有输出时间步上的特征贡献度
se.plot(method='IV', figsize=(30, 5))
